
Back to: The Data Aspect of AI
The Importance of Data in AI
Artificial Intelligence is changing the way we interact with technology, from chatbots to self-driving cars. But have you ever wondered what makes AI so powerful? The answer is data. Just like a chef needs fresh ingredients to create a great dish, AI needs high-quality data to function effectively. In this lesson, we will explore why data is crucial for AI, the different types of data AI uses, and how data quality impacts AI performance.
AI functions as a learning system that improves with experience, and this experience is shaped by the data it processes. Think of AI as a car. The engine is the AI model, and the fuel is the data. Without high-quality fuel, even the best engine will not perform well. Similarly, AI models are only as good as the data they are trained on. When an AI system is exposed to biased, incomplete, or low-quality data, its decision-making processes will reflect those deficiencies, leading to unreliable or even harmful outcomes.
Types of Data in AI
Data used in AI can be categorized into different types based on how it is structured and stored.
- Structured Data is highly organized and easily stored in tables or databases. It consists of clear formats that allow for easy searching and sorting. Examples of structured data include spreadsheets, customer databases, and financial records. AI models utilize structured data for tasks like fraud detection, customer segmentation, and predictive analytics.
- Unstructured Data does not follow a fixed format and requires preprocessing before AI can use it. This type of data includes images, videos, emails, and social media posts. Since unstructured data is not inherently organized, AI must use advanced techniques like natural language processing, computer vision, and deep learning to make sense of it. AI applications such as facial recognition, speech-to-text systems, and recommendation engines rely heavily on unstructured data to function effectively.
- Semi-Structured Data falls between structured and unstructured data. It contains some level of organization but does not adhere to a strict schema like structured data. Common examples include JSON, XML files, and sensor logs. AI systems process semi-structured data in applications such as web applications, IoT device monitoring, and chatbot interactions. Unlike structured data, semi-structured data requires additional processing steps to extract meaningful insights before being used for training AI models.
The Role of Data Quality
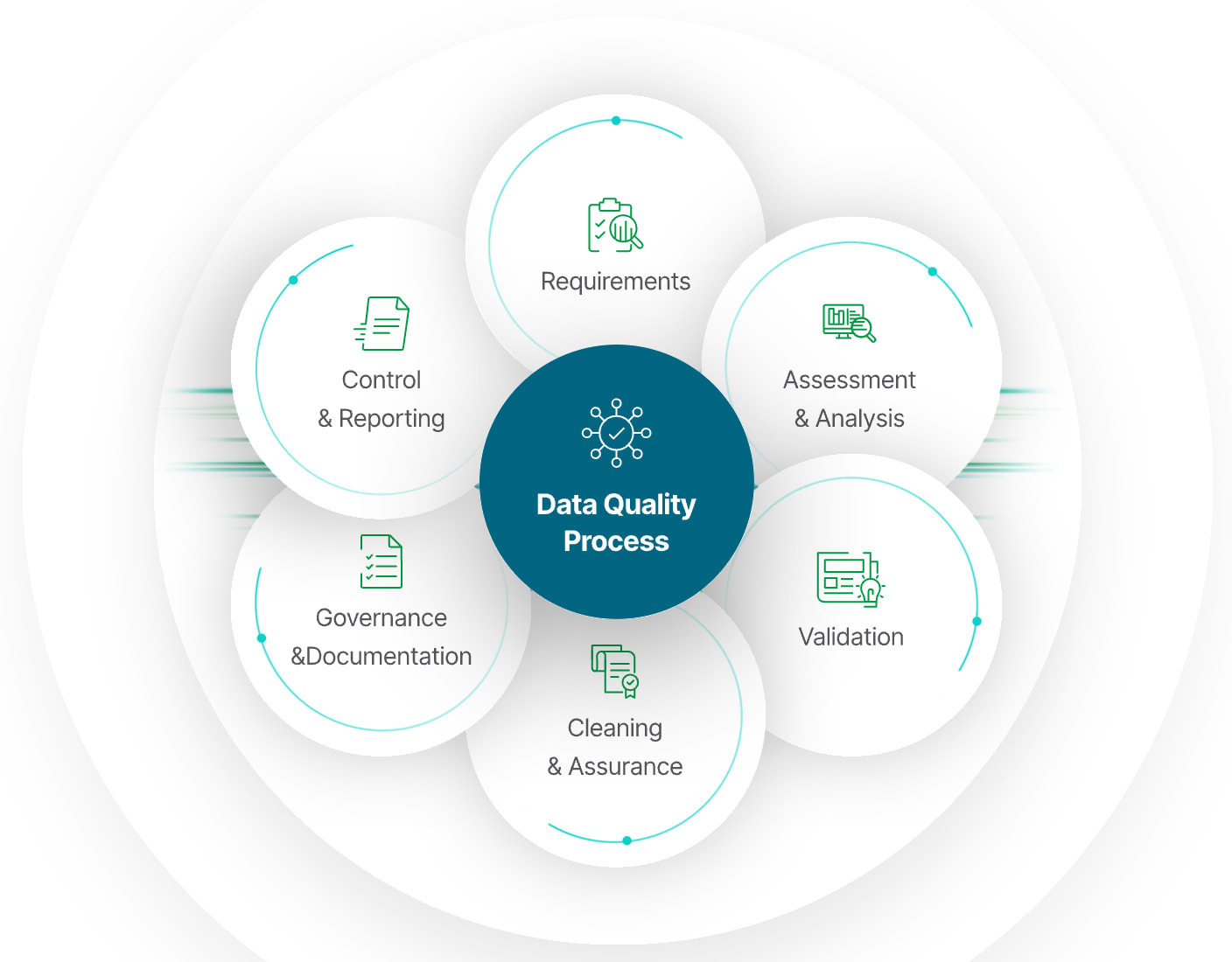
Data quality is one of the most important factors in determining the success of an AI system. The phrase “Garbage In, Garbage Out” is commonly used in AI development, emphasizing that poor-quality data will result in unreliable AI outputs. The key attributes of high-quality data include:
- Accuracy ensures that the data is correct and free of errors.
- Completeness ensures that there are no missing values or gaps in information.
- Consistency means that the data follows a uniform format and is not conflicting.
- Timeliness ensures that the data is up-to-date and relevant to current circumstances.
- Bias-Free data is essential for fair and ethical AI decision-making, as biased data can lead to discrimination and flawed predictions.
Challenges of Biased Data
One real-world example of data bias can be seen in facial recognition technology. Several studies have shown that early versions of facial recognition systems struggled to correctly identify individuals from diverse backgrounds due to an overrepresentation of light-skinned individuals in the training datasets. This lack of diversity led to higher error rates when recognizing people with darker skin tones. Addressing such biases requires collecting diverse, representative data that reflects the full spectrum of human demographics. AI developers must actively seek out and correct biases to create more equitable and effective systems.
The AI Data Lifecycle
The journey of data in AI follows a structured lifecycle, beginning with data collection. AI systems gather data from various sources, including sensors, databases, and web scraping methods. Once collected, the data is stored in cloud systems or databases to ensure it remains accessible for analysis and training.
After storage, data must be cleaned to remove errors, duplicate entries, and inconsistencies. Cleaning is a crucial step, as poor-quality data can significantly degrade the performance of an AI model. Preprocessing steps ensure data meets the format and structure required by AI algorithms. These steps can include:
- Normalization to adjust data values into a common scale.
- Feature extraction to identify the most relevant information from raw data.
- Encoding categorical variables to convert non-numeric data into a format AI models can interpret.
In some cases, data augmentation is used to artificially increase the size of the dataset. This is particularly useful in image recognition tasks where additional variations of images can be generated through transformations like rotation, flipping, and color adjustments. Augmented data helps improve the robustness of AI models by exposing them to a wider range of input variations.
Copyright 2025 MAIS Solutions, LLC All Rights Reserved